Итак, что такое интерфейс? Если вдуматься в звучание этого слова, то это что-то inter face, т.е. находящееся между взаимодействующими субъектами. И это действительно так. Интерфейс есть спецификация способа взаимодействия двух сущностей понятным для них обеих образом. (И всегда - двух и только двух! Пару могут составлять всё время разные объекты в разном сочетании, но спецификация распространяется только на inter face...)
Концепция интерфейса (а это именно концепция) является абстракцией не меньшего, а может даже - и большего, уровня, чем абстракция объекта. Она требуется, когда мы от взаимодействия объектов переходим к конструкции какого-то одного из них. В таком случае интерфейс выступает, как существенные исключительно для взаимодействия стороны второго, не рассматриваемого в данный момент, объекта. Например, во взаимодействии телефонного аппарата и телефонной станции интерфейсом, очевидно, является вид и последовательность сигналов, которыми обмениваются аппарат и станция. Станцию не интересует цвет, вес, форма и прочие свойства аппарата. Станция считает телефонным аппаратом любой объект, который в состоянии "по проводам" передавать сигналы установленной спецификации. Аналогичная картина наблюдается и со стороны телефонного аппарата - для него станция тоже приводится только к сигналам, которые он получает из линии, а где она расположена, какое у нее здание и что у нее есть еще - аппарат не знает, да ему это и не нужно.
Другой пример интерфейса показывает обычная пара - штепсельная вилка и штепсельная розетка. Вместе они составляют "разъёмное соединение", но на стороне каждого из взаимодействующих объектов имеется своя спецификация - штыри или гнезда определенного размера и на определенном расстоянии. Розетка вполне может считать вилкой любой предмет, который имеет штыри определенного диаметра, расположенные на определённом расстоянии, а вилка может считать розеткой любые гнезда, способные вместить её штыри.
Из этих примеров должно быть понятно, что интерфейс является вполне точной категорией, но не имеет никакого особенного вещного выражения. Весь интерфейс выражается только в спецификации, как должны взаимодействовать объекты и что они должны иметь и делать для этого взаимодействия.
Концепция интерфейса замечательна тем, что она позволяет разделить способность объекта к взаимодействию и другие свойства данного объекта. Если вернуться к примеру телефонного аппарата, то его весьма специфическое восприятие телефонной станцией приводит к тому, что и факсимильная машина и модем и вообще всё, что угодно, способное произвести в линию заданную последовательность сигналов требуемого уровня и вида будут способны воспользоваться услугами телефонной станции. А это даёт определенную свободу в конструировании этих устройств без переделки конструкции телефонной станции. Либо, напротив - свободу в переделке конструкции телефонной станции без потери ею способности обслуживать телефонные соединения.
Интерфейсами пропитана вся наша окружающая жизнь. Мы используем это понятие как совершенно естественное, часто не отдавая себе сознательного отчета в том, что оно называется "интерфейс". Скажем, многие ли вспомнят, что обычный телефонный аппарат имеет и второй интерфейс? Интерфейс между человеком и аппаратом! Этот интерфейс выражается в приемопередающей звукопреобразующей аппаратуре (микрофон и телефон), устройстве, генерирующем вызывные сигналы (номеронабиратель), а ещё - в последовательности действий, которые нужно произвести, чтобы установить соединение с удалённым корреспондентом. Если не будет хотя бы чего-то одного, если последовательность действий будет нарушена - соединение не состоится. А это - это и есть самый настоящий интерфейс, поскольку "что у аппарата внутри" в данном случае никак не влияет на возможность установления связи.
С другой стороны, интерфейс - действительно философское понятие. То что, является самостоятельным объектом на одном уровне рассмотрения, на другом уровне вполне может оказаться только лишь другим интерфейсом, а то и его частью. Например, когда вы звоните в билетную кассу, чтобы заказать билет в театр, то "весь телефон" для вас окажется просто частью бОльшего интерфейса между вами и билетным кассиром с той стороны. И у вас будет "способ взаимодействия", в котором "вхождение в телефонную связь" будет рассматриваться только как часть общего алгоритма взаимодействия. И не состояться это взаимодействие может по совсем другим причинам, например, кассир с той стороны говорит на языке, которого вы не понимаете, хотя - в связь при помощи телефона вы оба входите совершенно правильно.
Поскольку интерфейс - категория философская, то и в программировании можно найти его примеры на каждом шагу. Хотя они и не называются так, тем не менее, ничем, кроме интерфейса они и не являются. Самый распространённый пример называется "прототип функции". Если припомнить как описывается разбиение программы на "вызывающую" и "вызываемую" функции, то там фигурируют такие понятия, как "вызов функции", "определение функции" и "описание прототипа функции". При этом дело обстоит так, что для компиляции вызова функции не требуется её определения, достаточно "описания прототипа". Прототип так же полезно показать компилятору и при определении функции - тогда компилятор будет способен заметить расхождения между "прототипом" и фактическим определением. Что же есть в данном случае одна строчка "прототип функции"? Да интерфейс же! Ведь он ничего не делает, кроме как описывает существенные для взаимодействия с этой функцией свойства - имя функции, тип возвращаемого значения, порядок следования и типы аргументов.
Следует заметить, что при описании взаимодействия в computer sciences разделяют два понятия - "интерфейс" и "протокол". Первое из них обозначает статику этого взаимодействия, т.е. что именно, в каком формате и на каком месте должен предоставлять объект. Второе обычно обозначает динамику взаимодействия - чем именно и в какой последовательности должны обмениваться взаимодействующие объекты. Это разделение существует, оно традиционно, хотя… хотя и интерфейс и протокол относятся к одному и тому же явлению. И когда их иногда смешивают в одну сущность (которую называют то "интерфейс", то "протокол") в этом нет особенной ошибки. В самом деле, чем "спецификация в пространстве" (интерфейс) отличается в своей сущности от "спецификации во времени" (протокол)?
Итак, первым китом компонентного программирования является понятие объекта. Понятие явно определенного интерфейса - второй его кит.
Что такое интерфейс в его программном исполнении? Ответ на него может быть и длинным и коротким - мы видели, что даже объявление прототипа функции уже можно считать интерфейсом. И программирование пользуется этим очень давно.
В действительности же интерфейс стали называть отдельным специальным словом тогда, когда стало очевидно - сложность программных конструкций стала такой, что программист уже не может удержать во внимании оба взаимодействующих объекта. Пока это удавалось "объявление функции" выполняло страхующую роль - а вдруг где забыто чего? Но программист не чувствовал ни малейших неудобств в произвольном изменении списка аргументов функции - если по ходу развития программы требовалось этот список изменить, то он менял его в определении функции и в её объявлении. После чего запускал компилятор и тот показывал ему список мест, где нужно поправить.
Проблемы начинались тогда, когда, образно говоря, "задачи стали занимать более десяти тысяч строк". Эти задачи уже не помещались в один "программный проект". Классическим же примером этого опять является "клиент-сервер" - его наиболее удобная реализация как раз и выглядит в виде двух самостоятельных программных проектов - проекта клиента и проекта сервера. А границу между проектами компилятор преодолевать не умеет…
Это, конечно, случилось совсем не вдруг - разработчики языков программирования видели эту проблему и пытались предложить для нее адекватное своему времени решение. Например, в языке C++ есть понятие чисто абстрактного класса, которое совершенно явно вводит понятие интерфейса между объектами. Оно в самом буквальном смысле явилось предтечей интерфейса COM и на нём стОит остановиться подробнее. Давайте кратко рассмотрим откуда возникла эта проблема и в чём она состоит.
Рассмотрим класс (статический тип), описывающий объект сервера:
class Foo { int a; float b; };
и рассмотрим код клиента:
Foo Cls; Cls.a = 12; Cls.b = 13.2;
Это, как теперь канонически признаётся - нехороший код. Нехорошо иметь прямой доступ к данным класса помимо самого класса. Что вот будет, если нам придётся переименовать a - уж больно это невнятный идентификатор? "По науке" нам нужно делать только так:
class Foo { public: void SetA(int i) { a = i; } void SetB(float f) { b = f; } void SetAB(int i, float f) { a = i; b = f; } private: int a; float b; };
Теперь исполнить предложение в теле клиента:
Cls.a = 12;
не даст компилятор - данные-то у нас - private. Клиент придётся переписать:
Foo Cls; Cls.SetA(12); Cls.SetB(13.2);
В таком случае клиент наш может ничего и не знать о том, что такие переменные, как a и b в классе есть. Но для того, чтобы клиент мог быть откомпилирован, чтобы компилятор сумел правильно организовать вызов методов SetA и SetB , при его компиляции нам всё равно придется подавать на вход компилятору определение класса. Допустим, что мы поместили его в заголовочный файл myobj.h, который мы будем подавать компилятору и при компиляции кода сервера и, естественно, при компиляции кода клиента. Теперь у нас есть три файла исходного текста:
Первый:
//myobj.h - определение объекта Foo class Foo { public: void SetA(int i); void SetB(float f); void SetAB(int i, float f); private: int a; float b; };
Второй:
//myobj.cpp - реализация методов объекта сервера #include "myobj.h" void Foo::SetA(int i) { a = i; } void Foo::SetB(float f) { b = f; } void Foo::SetAB(int i, float f) { a = i; b = f; }
Третий:
//myclient.cpp - реализация кода клиента #include "myobj.h" Foo Cls; Cls.SetA(12); Cls.SetB(13.2);
Видите ли вы здесь неудобство, которое при этом возникает? А неудобство-то вот какое - при компиляции сервера нам действительно нужно знать всё про класс - и про его данные и про его методы. А вот при компиляции клиента нас интересуют только методы - данные-то сервера нам недоступны. И если в процессе развития сервера мы, скажем, добавили в класс еще одну, сугубо внутреннюю, переменную или внутренний метод, то понятно, что нам нужно будет перекомпилировать сервер. Но ведь нам также придется и перекомпилировать клиент - файл myobj.h ведь изменился! А вот сам клиент - не изменялся. А перекомпилировать клиент - придётся... Здесь это неудобство маленькое, но вот если и клиент и сервер - большие проекты, то эти сугубо локальные изменения могут вылиться и всегда выливаются в очень большие глобальные затраты. Ведь при изменении одного сервера приходится перекомпилировать всех его клиентов. Которые, при каком-то ощутимом их размере, уже не помещаются в единый проект и должны быть распределены по нескольким. Как быть? По сути, нам всего-то надо - разделить описания методов и данных, причем так, чтобы описание методов влияло и на клиент и на сервер, но полное описание класса - не влияло на клиент. Ведь из клиента мы видим только методы!
Это можно сделать воспользовавшись аппаратом абстрактных классов С++. Этот аппарат специально для этой цели и был сконструирован. Абстрактный класс, это класс который вводит только точные описания методов, причём их реализация откладывается до тех пор, пока от абстрактного класса кто-то не унаследуется. Вот тогда-то абстрактный класс заставит наследника в точности эти методы и реализовать! Попробуем усовершенствовать наше творение:
//myobjint.h - описание методов Foo class FooInterface { public: void SetA(int i) = 0; void SetB(float f) = 0; void SetAB(int i, float f) = 0; };
Далее, переписываем наши файлы:
Первый:
//myobj.h - определение объекта Foo #include "myobjint.h" //включили описание от которого наследуемся class Foo : public FooInterface { public: void SetA(int i); void SetB(float f); void SetAB(int i, float f); private: int a; float b; };
Второй:
//myobj.cpp - реализация методов объекта сервера #include "myobj.h" //включили описание всего объекта void Foo::SetA(int i) { a = i; } void Foo::SetB(float f) { b = f; } void Foo::SetAB(int i, float f) { a = i; b = f; }
Третий:
//myclient.cpp - реализация кода клиента #include "myobjint.h" //включили только описание как вызывать объект Foo Cls; Cls.SetA(12); Cls.SetB(13.2);
Мы запускаем третий наш файл myclient.cpp на компиляцию и... файл не компилируется! Компилятор сообщает, что класс Foo компилятору неизвестен. Верно. Нет у нас такого класса. У нас вместо него теперь - FooInterface, заменяем, компилируем. Стало ещё хуже - компилятор заявляет, что он вообще не может создать объект такого класса, т.к. класс... абстрактный... Это - очень интересное заявление! В чём же дело?
А дело вот в чём. FooInterface - действительно абстрактный класс. У него нет ничего, кроме объявления как вызывать методы. Методы чьи? Да наследника же, своих-то нет! Поэтому мы и не можем создать объект абстрактного типа - нет в нем ничего, что вызывать - неизвестно. Зато - совершенно точно описано - как вызывать. И, если мы получим каким-то образом указатель на наследника, то пользуясь спецификацией "как вызывать" предоставляемой абстрактным классом, мы все сделаем отлично:
//myclient.cpp - реализация кода клиента #include "myobjint.h" //включили только описание как вызывать объект FooInterface *pCls; //здесь нужно как-то получить значение для указателя pCls pCls->SetA(12); pCls->SetB(13.2);
И теперь, как бы ни развивался объект сервера, если спецификация абстрактного класса не изменялась нам ничего не нужно в клиенте изменять - ни в тексте, ни в его коде. Всё будет работать! Здорово? Осталось только-то получить указатель. Например, можно использовать оператор new:
pCls = new Foo();
Но... статический тип Foo нам на стороне клиента неизвестен. И пока мы не включим в состав своего клиента описание myobj.h нам не исполнить этого new. А ведь именно включения этого файла в код на стороне клиента мы и хотели избежать. Выходит, хотели как лучше, а получилось - как всегда? И что делать?
Прежде чем продолжить, я хочу особо отметить - описанное обстоятельство "свернуло шею" не одному программисту! Разнести описания клиента и сервера по разным файлам - очевиднейшее решение, оно недостойно даже особого упоминания. Вот только что делать с этим потом?
А вот этот вопрос не имеет прямого и однозначного ответа! Например, если наш код клиента - функция, то можно передать этот указатель как аргумент при вызове, только ведь где-то этот указатель первично получать всё равно придётся. Что вообще можно сделать? К сожалению, нужно признать, что в данном случае и сделать ничего нельзя. Причина этого - исключительно философская. Причина в том, что объект сервера Foo мы пытаемся создать в коде клиента - ведь new исполнятся на клиентской стороне? А поэтому абстрактные классы здесь нам помогут очень слабо - где-то, где будет выполняться new, всё равно потребуется иметь описание статического типа Foo, т.е. если тотальной перекомпиляции всех файлов проекта(-ов) ещё можно избежать, то вот тотальной перелинковки - никогда.
Именно поэтому аппарат абстрактных классов, введённый в C++, и не стал действительно аппаратом абстракции. Он - очень полезен при проектировании большой иерархии классов, но его власть над реализацией всё равно не может выйти за пределы одного проекта.
Вот если бы, сохранив преимущества абстрактного класса - точное описание "как вызывать", ещё и как-то избавиться от его недостатков - от необходимости на клиентской стороне знать "что вызывать" мы бы получили… мы бы получили интерфейс. Ведь абсолютное безразличие к "что", но с точным определением "как" это и есть интерфейс!
Мы обнаружили - абстрактный класс очень хорошо, просто замечательно, описывает технологию взаимодействия с объектом любого производного статического типа, выстроенного на базе этого абстрактного класса. Да только вот всё равно - для полноценного обращения с объектом знания абстрактного класса недостаточно, поскольку нам обязательно нужно знать ещё и полное описание этого класса.
Как избавиться от этого недостатка? Давайте подумаем. И подумаем не так, как принято в стандартном "по-проектном мышлении", а - именно с позиций подхода "клиент-сервер".
Во-первых, очевидно, что абстрактный класс нисколько не мешает обращаться к объекту, какого бы типа он ни был. Нужно просто иметь указатель на объект (это будет "что") и пользуясь абстрактным классом вызывать его методы (это будет "как"). Поскольку получить указатель - совершенно рядовая операция, трудность находится не в указателе. А как раз в том, на что он указывает. Мы не можем сделать объект оператором new потому, что оператор new должен знать не абстрактный базовый класс, а полное описание. Стоп! "...не можем..." где? Мы не можем это сделать на стороне клиента, т.к. мы и хотим избежать на стороне клиента именно полного описания класса! Но ведь на стороне сервера мы и не собирались этого избегать... Нас вполне устраивает, что неполное описание класса на стороне клиента, позволяет клиенту только лишь с объектом взаимодействовать. Вот, если бы еще сервер сам и делал этот объект, а потом передавал клиенту только указатель на него?
Это - правильная идея. Вся наша проблема только и заключается в том, что мы не можем породить объект сервера на стороне клиента. Но ведь это не означает, что мы не можем из клиента попросить сервер сделать нам объект указанного типа? Делаем в составе сервера специальную особую функцию, передаем ей тип объекта, который мы хотим получить. Сервер - заведомо знает все объекты, которые он реализует. Следовательно, сервер запрошенный объект создаст, передаст указатель клиенту, клиент применит к нему правила обращения, описываемые абстрактным классом - и проблема-то решена. Верно?
Нет! В C++ статический тип исчерпывающе описывается классом. А абстрактный класс - "не тот тип", иначе его бы не отказался использовать и сам оператор new. А new - отказывается. Поэтому для "функции сервера, умеющей создавать объекты" абстрактный класс будет всё так же неприменим, как и для "функции клиента".
Но и это - одолимая беда. Сервер же не реализует бесконечное множество статических типов объектов? Перенумеровать их - и всего-то. И запросы ставить к нему - "сделать объект типа номер один", "сделать объект типа номер три"… Только здесь возникает вот какое обстоятельство - чтобы корректно использовать "перенумерование" мы, фактически, должны использовать пары "статический тип на стороне сервера - абстрактный тип на стороне клиента" и перенумеровывать уже пары. А это - еще хуже, поскольку малейший сбой в соответствии частей останется незамеченным никем, но в большом проекте приведет к тому, что будет непонятно даже где ошибку и искать... Тупик?
Пройдемся ещё раз - по шагам. Мы не можем создать объект даже "внутри сервера" потому, что "внутри клиента" не знаем описания его статического типа ... "внутри сервера". Это мы так захотели - мы не хотим в клиенте об объекте сервера знать больше, чем тот абстрактный тип, который позволяет с этим объектом взаимодействовать. Меньше знаешь - реже перекомпилируешься. И отказываться от этого требования мы не собираемся. Но, с другой стороны, сервер-то как раз знает и полное описание статического типа, и тот абстрактный тип, на базе которого этот статический тип построен. Почему бы нам не отправлять на сервер запросы примерно такого вида - "создать объект статического типа номер четыре, построенный на базе абстрактного типа XXX"? У сервера эта информация есть. Пусть не мы на клиентской стороне, но сам сервер отслеживает соответствует ли номер статического типа абстрактному типу и может ли он такой объект создать. Поэтому, похоже, выход находится здесь - на стороне клиента нумеровать (именовать не описанием классов) статические типы и отправлять на сервер запросы из пар "номер объекта - абстрактный тип". Когда сервер "сделает из номера" настоящий объект и передаст указатель на него клиенту, то клиенту будет уже всё равно, какой там у этого статического типа был номер, он будет применять при доступе по этому указателю исключительно абстрактный тип, который он заказывал. Эврика? Эврика...
Всё бы хорошо, да вот... Абстрактный класс - понятие времени компиляции. А создание экземпляра статического типа - понятие времени выполнения, когда никакого абстрактного класса уже и в помине нет. Способ борьбы понятен - перенумеровать и абстрактные типы так же, как перенумеруются сами статические типы, и передавать серверу пару "номер статического типа - номер абстрактного типа". Только способ этот не сработает - именно потому, что абстрактный класс есть понятие времени компиляции. В откомпилированном модуле нет никаких классов, а есть "данные + код". Пока связывание было "ранним" - на этапе компиляции и линковки, такой способ годился. Потому, что все описания классов приводились компилятором к таблицам смещений, которые он сам же и подставлял в код. А сейчас у нас связывание "позднее" и те самые таблицы компилятора уже давно не существуют... Иными словами наш славный абстрактный класс не годится только потому, что он существует лишь "в воображении компилятора" и не существует во время исполнения. И "номер абстрактного типа" - номер сущности, которой нет в тот момент, когда на неё ссылаются. А есть ли "абстрактные структуры", существующие и во время исполнения тоже?
Есть! Есть такие структуры и самое парадоксальное, что они как раз и были придуманы в языке C++ для решения именно той самой проблемы, которую мы с таким трудом пытаемся решить - как сказать компилятору "как" не говоря "что". Как до поры разделить построение и использование объекта. Это - виртуальные функции.
С++ - мощный язык. Мощный в том смысле, что он позволяет "по человечески естественно" выражать генетические отношения между статическими типами. Это - азбука C++ и на эту тему давно написано много, со вкусом, и в разных стилях. Так что повторять это здесь даже как-то и неудобно. И есть в C++ одна интересная особенность - в иерархии наследования можно определить такую конструкцию, что программа, располагающая объектом базового класса во время исполнения будет вызывать методы не самого этого, но производного от него класса. Традиционно этот случай иллюстрируется примером, когда определяется класс "геометрическая фигура", от него наследуются классы "круг", "треугольник", "квадрат" и в базовом классе определяется метод "рисовать фигуру". Но - какую именно фигуру класс "геометрическая фигура" не знает, зато это знают класс "круг" и другие - ведь они-то себя как раз рисовать и умеют. Как сделать по человечески совершенно естественную вещь - сделать так, чтобы один и тот же метод "рисовать фигуру", принадлежащий классу "геометрическая фигура", ничего не знающему о том, какие классы ещё только будут от него произведены, начал "рисовать фигуры" производных классов?
Столь сложная, на первый взгляд, проблема решается до неприличия просто - вместо простого внутреннего смещения метода "рисовать фигуру" в базовом классе компилятор генерирует настоящий указатель. И генерирует к нему пометочку - адрес метода производного класса поместить в этот указатель, принадлежащий базовому классу. Так что, когда от данного базового производится класс-потомок, компилятор видит, что адрес метода потомка нужно занести и в этот самый указатель тоже. Когда программа будет вызывать такой метод базового класса она, фактически, совершит косвенный переход по указателю на метод не базового класса, но - его потомка. Это - классика, о ней подробно можно прочитать в любом учебнике по C++, куда желающие отсылаются за бОльшими подробностями. Для нас же важно понять, что компилятор генерирует указатель, т.е. структуру, которая в таком случае существует как раз во время исполнения. А это - именно то, что нам требовалось - если сделать абстрактный класс виртуальным, то мы получим нужную нам абстрактную структуру существующую и после окончания компиляции.
Поэтому общее решение возникшей перед нами проблемы как разделить сервер и клиент будет таким:
Это - очень важное обстоятельство. Это - фундамент нулевого уровня на котором построен COM.
Давайте вспомним существо наших изысканий. Первое - мы захотели, чтобы спецификации статического типа, предъявляемые "при сборке сервера" отличались от спецификаций типа, предъявляемых "при сборке клиента". Мы выделили список методов доступа к объекту, влияющий и на клиент и на сервер, и выделили прочие части конструкции сервера, влияющие только на сервер. Второе - пользуясь списком методов, который мы упаковали в абстрактный класс, мы получили вполне работающий доступ клиента к серверу. Третье - мы не смогли решить проблему первоначального создания этого объекта клиентом - ни прямо в своем коде, ни косвенно - посредством изобретения специальной функции в составе сервера и хитрой системы именования. Мы решили её только при помощи "виртуальных абстрактных классов".
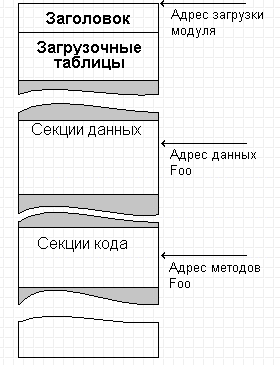
Начнём, естественно, с самого начала - программа, которую видит процессор есть последовательность двоичных чисел - команд процессора. Одну за одной он выбирает команды и совершает действия в них закодированные. Но это вовсе не означает, что двоичный файл, содержащий программу в машинных кодах, внутри никак не структурирован, что он представляет собой кусок просто "управляющей ленты" и только. Схематически конструкция загружаемого модуля (любой машины!) показана на рисунке:
Схема устройства двоичного исполняемого модуля
Можно видеть, что модуль имеет секционированную структуру - в нём есть заголовок, таблицы и секции (сегменты). Заголовок - служебная информация, описывающая загрузчику операционной системы с чем он имеет дело, как данный модуль должен загружаться в память и настраиваться для того, чтобы он мог быть выполнен. Таблицы - аналогичная информация, описывающая требования к окружению - какие ещё модули должны загружаться, чтобы данный мог выполняться, либо, наоборот, что данный модуль может предоставить в распоряжение других модулей. А вот секции - секции и есть собственно "части тела" нашей программы. Необходимость секционирования связана с тем, что двоичные данные имеют разную семантику - часть двоичных чисел действительно описывает "данные", а часть - команды процессора. Поскольку процессор "просто выполняет команды", то он не может отличить является ли двоичное число кодом команды программы или же - обрабатываемыми программой данными. Поэтому все данные собираются в один сегмент, а все команды - в другой. Сказанное - только очень примитивная иллюстрация, существует еще немало причин, по которым и данные и код должны быть структурированы по секциям и далее. Поэтому в составе исполняемого модуля обычно содержится несколько секций данных разного сорта и несколько секций кода, но для нас сейчас важно одно - данные и код на самом деле "разложены по разным карманам", они на стороне процессора не "прослаиваются" и вместе никогда не располагаются.
А вот на стороне программиста, в языке высокого уровня на котором он пишет программу, ситуация обратна - в его тексте данные и код группируются вместе, "прослаиваются" и следуют логике мысли программиста, а не семантике двоичных данных. Ввиду чего у программиста, не знающего истинного положения вещей, могут возникать некоторые иллюзии, изживаемые обычно долгими часами бесплодной отладки… Но на рисунке показано, что объект класса Foo будет разложен на "данные - отдельно, методы - отдельно", каким бы образом в исходном тексте что ни определялось.
Перевод программы из языка программиста на язык процессора выполняет специальная программа - транслятор. Транслятор принимает исходные предложения, записанные программистом, анализирует их и заменяет конструкции программиста равносильными конструкциями процессора. При этом транслятор ведет свои внутренние таблицы, в которых запоминает пары - "идентификатор - адрес двоичной конструкции". Всякий раз, когда в исходном тексте программист ссылается на идентификатор, транслятор на стороне процессора подставляет адрес из своей таблицы (называемый в таком случае ссылкой), соответствующий этому идентификатору.
Поскольку мы так лихо конспективно разобрались с "теорией синтаксического анализа, перевода и компиляции", посмотрим, как бы мог транслятор обрабатывать нашу программу - класс сервера Foo и его примитивного клиента, которые мы определили ранее. Соответствующий процесс показан на рисунке:
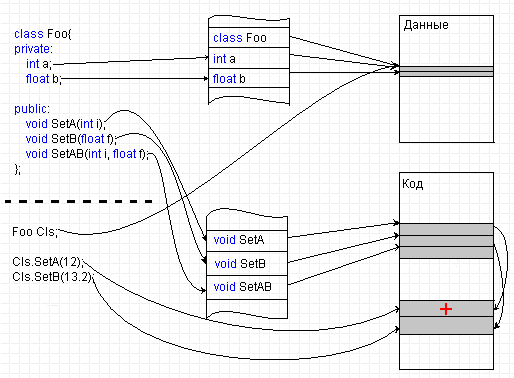
Схема построения исполняемого модуля
Слева на рисунке показаны предложения исходного текста. Справа - секции кода и данных формируемого исполняемого модуля. Ясности существа ради предполагается, что у нас нет линковки и транслятор сразу строит не объектный, а исполняемый код. Посередине изображены некоторые таблицы транслятора - таблица смещений данных и таблица смещений кода. На самом деле транслятор не занимается немедленным переводом, он еще проверяет и синтаксическую правильность конструкций, поэтому внутренних таблиц транслятора будет побольше, и связей между синтаксическими конструкциями, которые учитывает транслятор, тоже значительно больше. Но нам для иллюстрации принципа это совершенно неважно.
Итак, на вход транслятору попало описание нашего класса Foo. Транслятор проанализирует текст и где-то там себе отметит, что класс Foo состоит из двух элементов данных и трёх элементов процедур. Если они синтаксически правильны, то транслятор заполнит идентификаторами свои таблицы и расставит адреса данных класса относительно начала класса. Никакого кода здесь не порождается - вы знаете, что описание класса предназначено только транслятору.
Транслятор двигается дальше и видит в тексте модуля определения методов класса. Здесь они особо не показаны - только из соображений экономии площади рисунка. Располагаются они в месте, обозначенном жирным пунктиром - там же, где и другие конструкции программы. Ничего особенного в них нет, это - просто функции, связанные с классом. Методы - порождают код, поэтому транслятор в таблице смещений кода подставит в пару "идентификатор метода - адрес точки входа в него" адрес и откомпилирует текст, разместив команды в секции кода. Т.к. методы пока ниоткуда не вызываются, то это - тоже пока всё.
Дальше транслятор встречает определение объекта класса Foo Cls. Это предложение требует создать объект, т.е. отвести память под него и вызвать конструктор. Трансляция в этом и состоит - в сегменте данных транслятор отводит память и в таблице смещений данных помечает адреса, по которым он фактически разместил объект (вызов конструктора нас сейчас не интересует, а потому - пропускается).
Ещё дальше - предложение Cls.SetA(12). То самое предложение, ради рассмотрения трансляции которого всё это и написано! Трансляция состоит в вызове метода SetA в применении к объекту Cls. Перед кодогенерацией транслятор, конечно, убедится, что вызвать метод не запрещено правилами видимости и разделения доступа, что метод объекта Foo применяется действительно к экземпляру объекта Foo и т.д. - все эти ограничения являются синтаксическими, они не влияют на генерацию кода. А вот дальше начинается интересное - транслятор построит вызов CALL <адрес метода из секции кода> и передаст ему в качестве параметра <адрес объекта из секции данных>. Точнее, это будет пара примерно таких команд:
PUSH <адрес объекта из секции данных> CALL <адрес метода из секции кода>
На рисунке место, где компилятор будет их размещать обозначено плюсиком красного цвета. Обратите внимание - то, что объект из секции данных семантически соотносится с методом из секции кода нигде не отмечено - это знает только транслятор из собственных своих таблиц. Это он сам просто непосредственно подставляет в код адреса. Элементы же данных "сами" ничего не знают, где располагаются соответствующие им методы, а методы - не знают, где располагаются "их" элементы данных. Когда транслятор закончит свою работу и завершится, таблицы эти будут забыты, и никто не узнает, каким там был объект Foo, но останется правильно сочинённая программа. Для проектного программирования нам больше ничего и не требовалось - всё работает так, как было описано на языке высокого уровня.
Здесь должно также быть понятно, чем должен бы являться и чисто абстрактный невиртуальный класс (если бы таковой в языке C++ существовал) - он вообще ничего не порождал бы в коде, но он должен был бы заполнить таблицы транслятора, когда транслятор начинал разбор методов классов от него произведённых. И если транслятор углядел бы при этом несоответствие абстрактного класса производному от него - должна была возникнуть синтаксическая ошибка. И только! Однако, функциональность такого класса разработчики языка сочли избыточной - зачем, если всё то же, плюс еще кое-что полезное делает и виртуальный класс? И в языке в качестве абстрактного типа остался только виртуальный класс, что нисколько не вредит "потребительским качествам языка C++", но несколько затрудняет объяснение этой тонкой разницы для программистов не знающих Ассемблера.
Из описанной же схемы ясно следует, что при компонентной конструкции программ клиент, вызывающий <адрес объекта из секции данных> никак не сможет узнать <адреса объекта из секции кода > - соответствующих таблиц-то связывающих одно и другое уже и нет. Поэтому решение проблемы "как получить адрес метода моего класса" должно быть перенесено с компилятора на сам объект, в его составе должна появиться особая таблица - таблица, в которой находятся адреса методов, которые может вызывать клиент. Это - специальный указатель на функцию, генерируемый компилятором в составе статического типа, как только компилятор видит слово virtual в описании метода.
Более точно ситуация обстоит следующим образом - компилятор генерирует так называемую "таблицу виртуальных функций" (ее аббревиатура называется Vtbl), таблицу указателей по числу виртуальных методов, описанных в данном статическом типе. А в составе статического типа появляется указатель на эту Vtbl. Соответствующая микроархитектура показана на рисунке:

Двоичная микроархитектура объекта имеющего виртуальные методы
Вы видите, что в составе одного только объекта данных, входящего в состав статического типа теперь имеется и информация о методах этого объекта - адреса точек входа в них. А сам объект данных состоит из структуры данных и служебной таблицы Vtbl. Указатель на Vtbl в составе объекта данных генерируется компилятором всегда на одном и том же месте, поэтому просто знания того, что у класса должна быть Vtbl достаточно, чтобы компилятор правильно на неё сослался. Сама же Vtbl есть не что иное, как двоичная структура времени выполнения, соответствующая виртуальному абстрактному классу. Словом, для того, чтобы знать и данные объекта и его методы нам теперь вполне достаточно знать только указатель на сам объект, на рисунке это адрес "объекта Cls статического типа Foo". А для того, чтобы знать только методы объекта Cls нам достаточно извлечь из него ссылку на Vtbl. И сделать это можно и на клиентской стороне ничего не зная о данных, составляющих сам объект сервера.
Нужно так же сказать - на рисунке изображена совершенно точная двоичная структура "объекта экспонирующего интерфейс" на которой и построен COM. Единственная возможная здесь неточность - в какой именно памяти располагаются и сам объект данных и Vtbl класса. Здесь нарисовано, что они располагаются в статической памяти модуля, хотя это бывает (и значительно чаще!) и не так.
Отметим - предложенного решения вполне достаточно: компилятор на клиентской стороне всё построит правильно. Соединённая архитектура клиент-серверного взаимодействия с использованием такого механизма на нижнем уровне показана на рисунке:

Клиент-серверное взаимодействие посредством Vtbl
На этом рисунке показано, как имея указатель ptr на объект класса Foo компилятор в теле клиента будет вызывать метод SetA. Весь вызов сводится, по сути, только к двум командам процессора - извлечению из ptr ссылки на Vtbl и косвенному переходу по адресу в Vtbl. Там, где изображено жирное отточие компилятор вставит команды, соответствующие передаче аргументов вызываемому методу - они ничем не отличаются от команд, которые генерируются и при вызове "обычного" метода.
Обратите внимание - мы полностью добились того, чего хотели. Во-первых, между клиентом и сервером у нас "нет ничего общего", кроме описания таблицы виртуальных методов (виртуального чисто абстрактного класса). И клиент и сервер теперь могут разрабатываться, видоизменяться и компилироваться совершенно независимо. Но, как только изменится описание этой таблицы - и клиент и сервер должны быть пересобраны оба. Во-вторых, эта самая таблица является в чистом виде интерфейсом - она не описывает "что", это сообщает ссылка на объект - указатель, получаемый от сервера. Зато именно она описывает "как" - адреса-то самих вызываемых из секции кода методов берутся из нее самой. В-третьих, эта самая таблица - вполне "осязаемая" сущность, она существует во время исполнения и может быть перенумерована самостоятельным номером, так же, как мы нумеровали статические типы. В сущности, теперь мы располагаем всеми механизмами и микроархитектурными решениями для того, чтобы приступить к компонентному программированию.
Предыдущая Оглавление Следующая