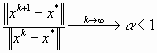 , то говорят о линейной сходимости с коэффициентом сходимости
α. Если
, то говорят о линейной сходимости с коэффициентом сходимости
α. Если 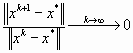 , то говорят о суперлинейной сходимости.
Если существует такое γ > 1, что
, то говорят о суперлинейной сходимости.
Если существует такое γ > 1, что 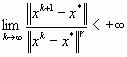 , то говорят о сходимости порядка
γ. В частности, если
, то говорят о сходимости порядка
γ. В частности, если 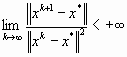 , то говорят о квадратичной сходимости.
, то говорят о квадратичной сходимости.Большинство методов решения задач оптимизации, которые мы будем рассматривать, имеет итерационную природу, т.е. исходя из некоторой начальной точки x0, они порождают потенциально бесконечную последовательность точек x0, x1, ..., xk, ..., которая, как мы рассчитываем, сходится к искомому оптимуму (экстремуму).
Алгоритм решения есть процесс, позволяющий, исходя из заданной начальной точки x0, строить последовательность x1,..., xk, ...,.
Будем говорить, что алгоритм глобально сходится (или обладает свойством глобальной сходимости), если для любой исходной точки x0 последовательность x1,..., xk, ..., порожденная данным алгоритмом, сходится к точке, удовлетворяющей необходимому условию оптимальности. Свойство глобальной сходимости выражает в некотором смысле надежность функционирования алгоритма.
Если глобальная сходимость установлена, то нас интересует оценка эффективности. С практической точки зрения эффективность алгоритма зависит от числа итераций, необходимых для получения приближения оптимума x* с заданной точностью ε. Если сравнить между собой большое количество алгоритмов и допустить, что время вычисления итераций одинаково для всех алгоритмов, то наилучшим среди них будет тот, который требует наименьшего числа итераций. К сожалению, оказывается невозможным сформировать общие правила такого рода сравнений. Природа оптимизируемой функции, значение выбранной точности, иерархия алгоритмов могут сильно различаться.
Если мы хотим получить критерий с некоторым абсолютным значением, то следует прибегнуть к другому типу анализа, взяв за объект исследования асимптотическую сходимость, т.е. поведение последовательности x1,..., xk, ... в окрестности предельной точки x*. Это приводит к тому, что каждому алгоритму приписывается некоторый индекс эффективности, называемый скоростью сходимости.
Если , то говорят о линейной сходимости с коэффициентом сходимости
α. Если , то говорят о суперлинейной сходимости.
Если существует такое γ > 1, что , то говорят о сходимости порядка
γ. В частности, если , то говорят о квадратичной сходимости.
Методы одномерного поиска используются в многомерных методах минимизации функций n переменных.
В этом методе предполагается, что функция f (x) дважды непрерывно дифференцируемая. Отыскание минимума
функции f (x) производится при помощи отыскания стационарной точки, т.е. точки x*,
удовлетворяющей уравнению
f '(x) = 0 при помощи метода Ньютона.
Если xk – точка, полученная на k-м шаге, то функция f '(x) аппроксимируется
своим уравнением касательной:
y = f '(xk) +
(x - xk) f ''(xk), а точка xk+1 выбирается
как пересечение этой прямой с осью Ох, т.е.
xk+1 = xk - f '(xk) / f ''(xk).
Неудобство этого метода состоит в необходимости вычисления в каждой точке первой и второй производных. Значит, он применим лишь тогда, когда функция f (x) имеет достаточно простую аналитическую форму, чтобы производные могли быть вычислены в явном виде вручную. Действительно, всякий раз, когда решается новая задача, необходимо выбрать две специфические подпрограммы (функции) вычисления производных f '(x) и f ''(x), что не позволяет построить общие алгоритмы, т.е. применимые к функции любого типа.
Когда начальная точка итераций x0 достаточно близка к искомому минимуму, скорость сходимости метода Ньютона в общем случае квадратическая. Однако, глобальная сходимость метода Ньютона, вообще говоря, не гарантируется.
Хороший способ гарантировать глобальную сходимость этого метода состоит в комбинировании его с другим методом для быстрого получения хорошей аппроксимации искомого оптимума. Тогда несколько итераций метода Ньютона, с этой точкой в качестве исходной, достаточны для получения превосходной точности.
Этот метод состоит в аппроксимации функции f '(x) не при помощи своей касательной в точке xk (как в методе Ньютона), а при помощи секущей – прямой, проходящей через точки с координатами (xk - 1, f '(xk - 1)) и (xk, f '(xk)). Тогда
xk + 1 = xk - f '(xk). (xk - xk - 1) / (f '(xk) - f '(xk - 1)).
Этот метод называется также методом хорд.
Глобальная сходимость метода секущих, как и метода Ньютона, не гарантирована. Стало быть, начальные точки x0 и x1 должны быть выбраны достаточно близкими к минимуму.
По отношению к предыдущим этот метод обладает тем преимуществом, что он не требует вычисления производных функции f (x). Однако, его сходимость может быть гарантирована лишь для достаточно регулярных функций (непрерывных и много раз дифференцируемых).
В этом методе вычисляется значение функции сразу в трех близлежащих точках x0 - h, x0, x0 + h, где h – малое число. Через эти три точки проводится интерполяционная парабола: y = ax2 + bx + c. Минимум параболы достигается при y = 2ax + b = 0, т.е. при x* = -b / (2a). Для трех точек получаем систему трех линейных уравнений для коэффициентов a, b, c. Находим a и b и тогда:
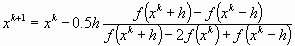 .
.
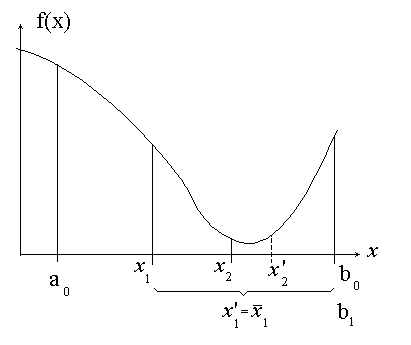
Теперь мы перейдем к рассмотрению других методов, более общих в том смысле, что они не требуют условия непрерывности или дифференцируемости. Они просто предполагают, что по крайней мере в некотором интервале функция f (x) обладает свойством унимодальности. Функция называется унимодальной на отрезке [a0, b0], если она монотонно убывает от a0 до некоторого x* из [a0, b0], а затем возрастает до b0. В этом случае x* соответствует локальному минимуму функции, и он единственный.
Пусть функция f (x) унимодальна на отрезке [a0, b0]. Необходимо найти точку минимума функции на этом отрезке с заданной точностью ε. Все методы одномерного поиска базируются на последовательном уменьшении интервала, содержащего точку минимума. Возьмем внутри отрезка [a0, b0] две точки x1 и x2: a0 < x1 < x2 < b0, и вычислим значения функции в этих точках. Из свойства унимодальности функции можно сделать вывод о том, что минимум расположен либо на отрезке [a0, x2], либо на отрезке [x1, b0]. Действительно, если f (x1) < f (x2), то минимум не может находиться на отрезке [x2, b0], если f (x1) > f (x2), минимум не может находиться на отрезке [a0, x1]. Если же f (x1) = f (x2), то минимум находится на интервале [x1, x2].
Алгоритм заканчивается, когда длина интервала, содержащего минимум, становится меньше ε.
Различные методы одномерного поиска отличаются выбором точек x1, x2. Об эффективности алгоритмов можно судить по числу вычислений функции, необходимому для достижения заданной точности.
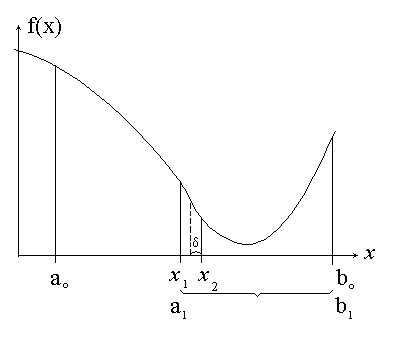
Точки x1, x2 выбираются на расстоянии δ < ε от середины отрезка:
x1 = (ai + bi - δ) / 2, x2 = (ai + bi + δ) / 2.
За одну итерацию интервал неопределенности уменьшается примерно в два раза.
За n итераций длина интервала будет примерно равна 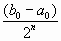 .
.
Для достижения точности ε потребуется 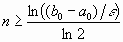 итераций.
итераций.
На каждой итерации минимизируемая функция вычисляется дважды.
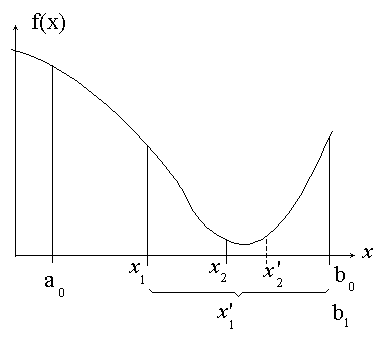
Точки x1, x2 находятся симметрично относительно середины отрезка [a0, b0] и делят его в пропорции золотого сечения, когда длина всего отрезка относится к длине большей его части также, как длина большей части относится к длине меньшей части:
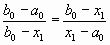 и
и 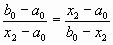 .
.
Отсюда:
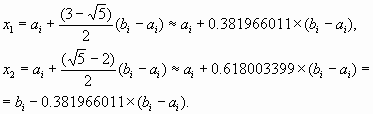
За одну итерацию интервал неопределенности уменьшается в 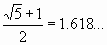 раз, но на следующей итерации мы будем вычислять функцию только один раз, так как по свойству золотого сечения
раз, но на следующей итерации мы будем вычислять функцию только один раз, так как по свойству золотого сечения
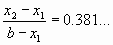 и
и 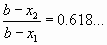 . Для достижения точности ε
потребуется
. Для достижения точности ε
потребуется 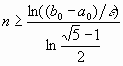 итераций.
итераций.
Неточное задание величины 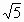 на ЭВМ уже при достаточно небольшом количестве
итераций может приводить к погрешностям и потере точки минимума, так как она выпадает из интервала
неопределенности. Поэтому, вообще говоря, при реализации алгоритма возможность такой ситуации должна быть предусмотрена.
на ЭВМ уже при достаточно небольшом количестве
итераций может приводить к погрешностям и потере точки минимума, так как она выпадает из интервала
неопределенности. Поэтому, вообще говоря, при реализации алгоритма возможность такой ситуации должна быть предусмотрена.
Числа Фибоначчи определяются соотношениями: Fn+2 = Fn+1 + Fn, n = 1, 2, 3, ...; F1 = F2. С помощью индукции можно показать, что n-е число Фибоначчи представимо в виде (формула Бинэ):
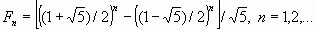
Из этой формулы видно, что при больших n: 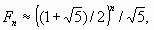 , так что числа Фибоначчи с
увеличением n растут очень быстро.
, так что числа Фибоначчи с
увеличением n растут очень быстро.
На начальном интервале вычисляют точки 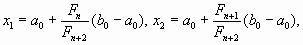 , где n выбирается исходя из
точности и начальной длины интервала (см. ниже).
, где n выбирается исходя из
точности и начальной длины интервала (см. ниже).
На k-м шаге метода будет получена тройка чисел 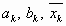 , локализирующая минимум
f (x), такая, что
, локализирующая минимум
f (x), такая, что 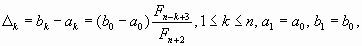 а точка
а точка 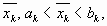 с вычисленным значением
с вычисленным значением
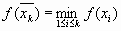 , совпадает с одной из точек
, совпадает с одной из точек 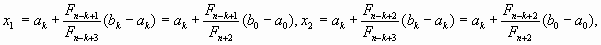
 расположенных на отрезке [ak, bk] симметрично относительно его середины. При
k = n процесс заканчивается. В этом случае длина отрезка
расположенных на отрезке [ak, bk] симметрично относительно его середины. При
k = n процесс заканчивается. В этом случае длина отрезка 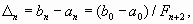 а точки
а точки
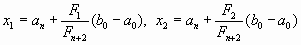 совпадают и делят отрезок пополам.
совпадают и делят отрезок пополам.
Следовательно, 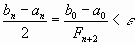 . Отсюда можно выбрать n из условия
. Отсюда можно выбрать n из условия 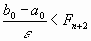 .
.
С ростом n, из-за того, что Fn/Fn+2 – бесконечная десятичная дробь,
происходит искажение метода. Поэтому на очередном шаге в качестве новой точки берут наиболее удалённую
от 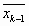 на предыдущем шаге.
на предыдущем шаге.
В рассмотренных методах требуется знать начальный отрезок, содержащий точку минимума. Поиск отрезка на прямой заключатся в том, что возрастающие по величине шаги осуществляются до тех пор, пока не будет пройдена точка минимума функции, т.е. убывание функции сменится на возрастание. Например, интервал может быть выделен с помощью следующего алгоритма.
Выбираем начальную точку x0 и определяем направление убывания функции.
Шаг 1. Если f (x0) > f (x0 + δ), то полагаем: k = 1, x1 = x0 + δ, h = δ. Если же f (x0) > f (x0 -δ), то x1 = x0 + δ, h = - δ.
Шаг 2. Удваиваем h и вычисляем xk+1 = xk + h.
Шаг 3. Если f (xk) > f (xk+1), то полагаем k = k + 1 и переходим к шагу 2. Иначе – поиск прекращаем, т.к. отрезок [xk-1, xk+1] содержит точку минимума.